HunyuanOCR 私有版本接入
特别说明
本章节内容为可选阅读,仅供参考。由于不同的硬件配置与部署环境可能存在差异,实际问题也会有所不同。建议按照本文环境及操作步骤执行,如遇异常可随时向 AI 寻求帮助,或咨询vllm官方,PIG AI 无法提供支持。
一、环境准备
1. 创建 Conda 环境
创建一个名为 vllm-fix 的 Python 3.11 环境:
2. 激活环境
依赖安装
3. 安装 PyTorch
使用阿里云镜像源安装 PyTorch 及相关组件:
4. 安装 vLLM
模型部署
5. 配置 Hugging Face 镜像源
设置环境变量以使用 Hugging Face 镜像站点:
6. 启动 vLLM 服务
使用以下命令启动 HunyuanOCR 模型服务:
参数说明
--no-enable-prefix-caching: 禁用前缀缓存--mm-processor-cache-gb 0: 将多模态处理器缓存大小设置为 0GB
首次运行说明
首次运行会自动从 HF-Mirror 下载模型(约数 GB),请耐心等待。默认服务地址:http://localhost:8000
三、在 PIG AI 系统中接入模型
- 登录 PIG AI 后台管理系统。
- 进入「模型管理」页面。
- 添加新模型,填写以下信息:
- 模型名称:
tencent/HunyuanOCR - 模型类型:多模态 OCR
- 服务地址:填写上一步中 vLLM 服务的 URL(如
http://localhost:8000/v1)
- 模型名称:

四、测试识别效果
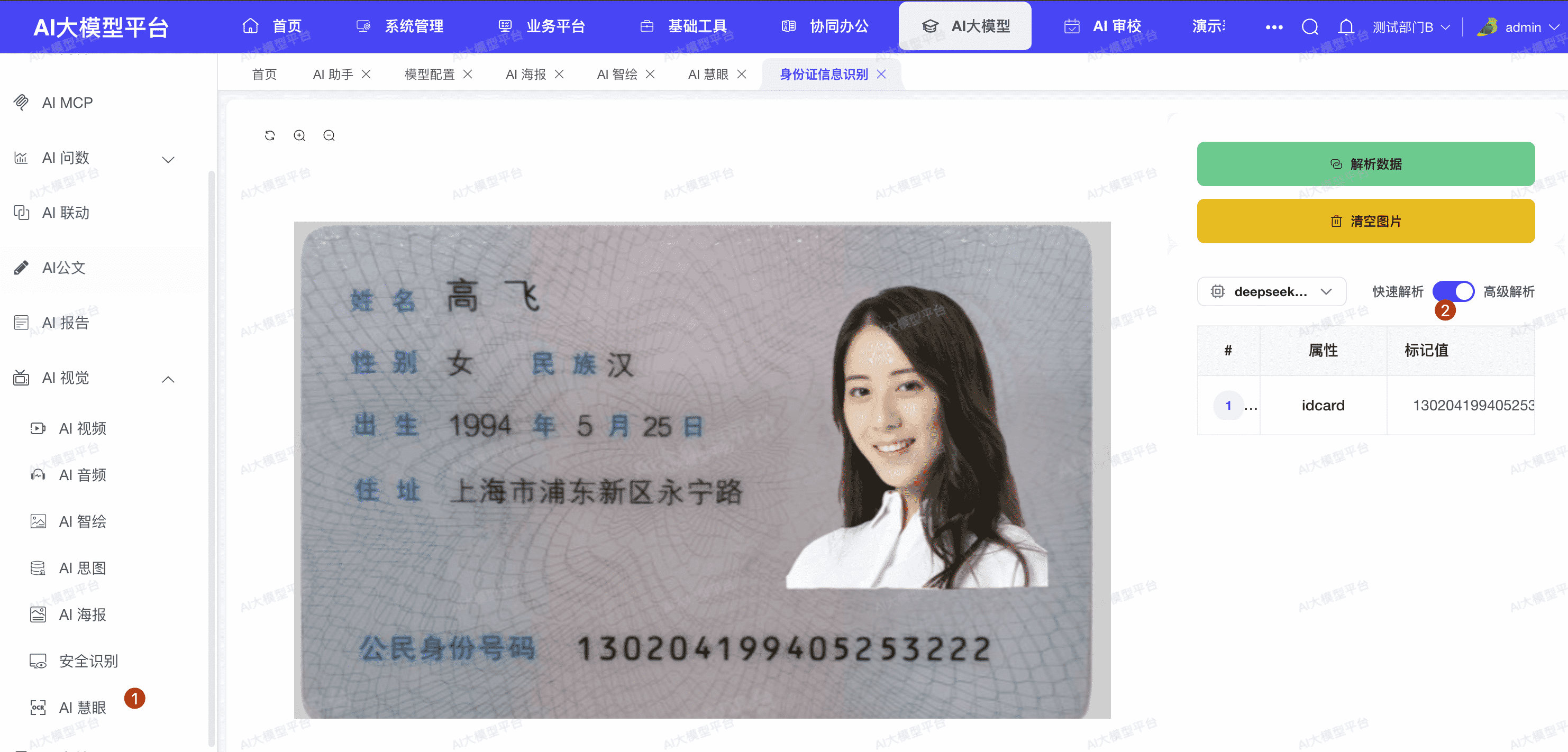
- 打开 PIG AI 的 AI 慧眼 功能。
- 上传一张包含文字的图片(如发票、表格、证件、截图等)。
- 建议开启“高级解析模式”(如有该选项),以获得更完整的布局还原。
结构化字段说明
若需结构化字段(如"发票号""金额"),需结合后处理规则或调用辅助模型进行解析。
本页目录